A Gentle Introduction to Javascript Test Driven Development: Part 1
This is part one of a three-part series outlining my personal approach to JavaScript Test Driven Development (TDD). Over the course of the series, I’ll work through developing a full application (albeit a small, simple one) in JavaScript that involves making network requests (also known as AJAX) and manipulating the DOM. The various parts are as follows:
- Part 1: Getting started with unit tests
- Part 2: Working with network requests in TDD
- Part 3: Working with the DOM in TDD
Why Test Driven Development?
Getting started with test driven development can be daunting. It sounds tedious, boring and hard. The word ‘test’ conjures up associations with exams and stress and invigilators and all kinds of unpleasantness. And it does seem like a waste to write code that doesn’t do anything useful other than tell you that the code you wrote is working. On top of all that, there’s also a confusing array of frameworks and libraries out there. Some work on the server; some work in the browser; some do both… it can be hard to know where to start.
The common predictable objections are “Writing unit tests takes too much time,” or “How could I write tests first if I don’t know what it does yet?” And then there’s the popular excuse: “Unit tests won’t catch all the bugs.” 1
There are, however, a lot of good reasons to give TDD a go. Here are three I think are important:
- It forces one to think. This is a lot more useful than it sounds. Writing a test forces me to think clearly about what I am trying to achieve, down to the level of detail that a computer can check. It forces me to be specific about what I’m trying to do. Once I’ve got that clear in my head, it becomes much easier to write the code. If I’m struggling to write a test, then I know that I haven’t fully understood the problem I’m trying to solve.
- It makes debugging easier. While TDD won’t cause you to write less bugs (sadly), it does make it much easier to track them down when they inevitably pop up. And if I then write a test related to that bug, it gives me confidence that I know I’ve definitely fixed that particular bug. And I can re-run all my other tests to check that my bug-fix hasn’t broken other bits of my code.2
- It makes coding more fun. In my mind, this reason far outweighs the other two. Practicing the simple steps of TDD is kind of addictive and fun. The discipline of TDD takes a bit of getting used to, but once you’ve got the hang of it, coding becomes more enjoyable.
Those aren’t the only reasons to take up TDD, but hopefully they are enough to convince you to give it a try. In a moment we’ll start working through a simple example, but first, let’s go over the basic outline of how it works.
What is TDD?
TDD is an approach to writing software where you write tests before you write application code. The basic steps are:
- Red: Write a test and make sure it fails.
- Green: Write the simplest, easiest possible code to make the test pass.
- Refactor: Optimise and/or simplify the application code, making sure that all the tests still pass.
Once we finish step 3, we start the cycle again by writing another test.
These three steps form the TDD mantra: ‘red, green, refactor’. We’ll examine each of these in detail as we go through an example. But first one final thing.
TDD is a form of self discipline—a life hack—it doesn’t magically make one a better coder. In theory, there’s no reason why a great coder couldn’t write exactly the same code as someone who doesn’t. But the reality is that the discipline of TDD strongly encourages one to:
- Write tests; and
- Write smaller, easier-to-understand units of code.
Personally, I find that if I’m not practicing TDD, I hardly ever write any tests at all, and the functions I write are larger and more complicated. That’s not to say I’m not testing—I’m hitting the refresh button in my one browser all the time—but my tests are useless to anyone else but myself.
A worked example
Let’s take a fairly typical JavaScripty-type thing to do as our example: Fetch some data from a server (in this case, a list of photos from Flickr.com), transform it to HTML, and add it to a web page. You can see the final result in action in this CodePen (with a dash of added CSS).
For this example, we’ll use the Mocha framework. I’ve chosen Mocha, not because it’s the most popular JavaScript testing framework (though it is); not because it is enormously better than other test frameworks (it isn’t); but for the simple reason that if I add the --reporter=nyan option on the command line, then my test report features a flying rainbow space cat. And that makes it more fun:
mocha --reporter=nyan
Setting up
For this tutorial, we’ll run all our tests on the command line using Node. Now you may be thinking, ‘Aren’t we writing a web application that will run entirely in the browser?’ And the answer is yes, we are. But running our tests in Node is much faster, and the differences between the browser and Node will help us to think carefully about how to structure the code (more on that later).
To get started, we will need Node installed, plus Mocha and one other module called Chai. If you are using MacOS, then I recommend using Homebrew to install Node, as it is easy to keep up to date. Once you’ve got Homebrew set up, you can install Node from the command line as follows:
$ brew install node
If you’re on Linux, then you can use your regular package manager system (like apt-get or yum) to install Node3.
And if you’re using Windows, then I recommend visiting the Node website, and grabbing the installer.
Once we have Node installed, we can use the Node Package Manager (npm) to install Mocha and Chai for us. Make sure to change to the directory where you are going to write your code, and run these commands:
cd /path/to/place/where/I/will/write/my/code
npm install mocha -g
npm install chai
Now that we have the prerequisites installed, we can start thinking about the application we want to build.
Thinking
So, while we said just a moment ago that there are only 3 steps to TDD, it’s not entirely true. There’s a step zero. You have to think first, then write a test. To put it another way: Before you write a test you have to have at least some idea of what you want to achieve and how you will structure your code. It’s test driven development, not test driven design.
Let’s first describe what we want to do in a little more detail:
- Send a request to the Flickr API, and retrieve a bunch of photograph data;
- Transform the data into a single array of objects, each object containing just the data we need;
- Convert the array of objects into an HTML list; and
- Add the HTML to the page.
Next I need to think about how to structure the code. Since it is a fairly simple task, I could put everything into one module. But, I have a few choices as to how I could perform the last two steps (making HTML and putting it into the page):
- I can change the DOM directly to add HTML to the page, using standard DOM interfaces;
- I could use jQuery to add the HTML to the page; or
- I could use a framework like React.js or a Backbone View.
Since I will probably use jQuery to make the HTTP request to the server, it seems (at this stage, anyway) that the simplest approach will be to use jQuery to manipulate the DOM. But, in the future I might change my mind and use a React component. So, it makes sense to keep the fetch-and-transform bit of the application separate from the make-HTML-and-add-to-DOM bit. So, I will create two modules: one for fetching the data and transforming it; and another for managing the HTML.
With this in mind, I’ll create four files to house my code:
flickr-fetcher.jsfor the module that fetches the data and transforms it;photo-lister.jsfor the module that takes the list, converts it to HTML and adds it to the page;flickr-fetcher-spec.jsfor the code to testflickr-fetcher.js; andphoto-lister-spec.jsfor the code to testphoto-lister.js.
Writing tests
With these files in place I can start thinking about writing my first test. Now, I want to write the simplest test possible that will still move my codebase forward. So a useful thing to do at this point would be to test that I can load the module. In flickr-fetcher-spec.js I write:
// flickr-fetcher-spec.js
'use strict';
var expect = require('chai').expect;
describe('FlickrFetcher', function() {
it('should exist', function() {
var FlickrFetcher = require('./flickr-fetcher.js');
expect(FlickrFetcher).to.not.be.undefined;
});
});
There are a few things to note here. First of all, because all these tests run using Node, this means that we import modules using the node-style require().
The next thing to note is that we are using a ‘Behaviour Driven Development’ (BDD) style to write the tests. This is a variation on TDD where tests are written in the form: Describe [thing]. It should [do something]. The [thing] can be a module, or a class, or a method, or a function. Mocha includes built-in functions like describe() and it() to make writing in this style possible.
The third thing to note is the expect() chain that does the checking. In this case I am checking simply that my module is not undefined. Most of the time though, the pattern I will use is expect(actualValue).to.equal.(expectedValue);.
So, let’s run the test:
mocha --reporter=nyan flickr-fetcher-spec.js
If everything is installed correctly, I see a happy cat like the one below.

Our test passes, which seems silly given that we haven’t written any module code. This is because my file flickr-fetcher.js exists (and Node gives you an empty object if you require a blank file). Since I don’t have a failing test though, I won’t write any module code. The rule is: No module code until there’s a failing test. So what do I do? I write another test—which means thinking again.
So, the first two things I want to achieve are:
- Fetch data from Flickr, and
- Transform the data.
Fetching data from Flickr involves making a network call though, so like a good functional programmer, I’m going to put that off until later.4 Instead, let’s focus on the data transformation.
I want to take each of the photo objects that Flickr gives us and transform it into an object that has just the information that I want—in this case, a title and image URL. The URL is tricky though because the Flickr API doesn’t return fully formed URLs. Instead, I have to construct a URL based on the size of photo I want. Now, that seems like a good place to start for the next test: Something small, testable, that will move the codebase forward. I can now write a test.
// flickr-fetcher-spec.js
var FlickrFetcher = require('./flickr-fetcher.js');
describe('#photoObjToURL()', function() {
it('should take a photo object from Flickr and return a string', function() {
var input = {
id: '24770505034',
owner: '97248275@N03',
secret: '31a9986429',
server: '1577',
farm: 2,
title: '20160229090898',
ispublic: 1,
isfriend: 0,
isfamily: 0
};
var expected = 'https://farm2.staticflickr.com/1577/24770505034_31a9986429_b.jpg';
var actual = FlickrFetcher.photoObjToURL(input);
expect(actual).to.eql(expected);
});
});
Note that I have used expect(actual).to.eql(expected); here rather than expect(actual).to.equal(expected);. This tells Chai to to check that every single value inside actual matches every single value inside expected. The rule of thumb is, use equal when comparing numbers, strings, or booleans, and use eql when comparing arrays or objects.
So I run the test again and… sad cat. I have an error. This means I can write some code. Step one is simply to get the module structure in place:
// flickr-fetcher.js
var FlickrFetcher;
FlickrFetcher = {
photoObjToURL: function() {}
};
module.exports = FlickrFetcher;
If I run my test now, I get a failure rather than an error, but the cat is still sad (red), so I can keep writing code. The question now is, what is the simplest possible code that I could write to make this test pass? And the answer is, of course, to return the expected result:
var FlickrFetcher;
FlickrFetcher = {
photoObjToURL: function() {
return 'https://farm2.staticflickr.com/1577/24770505034_31a9986429_b.jpg';
}
};
Run the tests again and everything passes—happy cat (green).
The next step is to refactor. Is there any way I can make this function more efficient or clearer? At the moment I think this code is probably about as clear and efficient as it can be. But, we all know this function is pretty useless. You may well be thinking “if you pass in any other valid object, that function would not work”. And that’s a very good point. I should write another test and pass in another valid object:
// flickr-fetcher-spec.js
describe('#photoObjToURL()', function() {
it('should take a photo object from Flickr and return a string', function() {
var input = {
id: '24770505034',
owner: '97248275@N03',
secret: '31a9986429',
server: '1577',
farm: 2,
title: '20160229090898',
ispublic: 1,
isfriend: 0,
isfamily: 0
};
var expected = 'https://farm2.staticflickr.com/1577/24770505034_31a9986429_b.jpg';
var actual = FlickrFetcher.photoObjToURL(input);
expect(actual).to.eql(expected);
input = {
id: '24770504484',
owner: '97248275@N03',
secret: '69dd90d5dd',
server: '1451',
farm: 2,
title: '20160229090903',
ispublic: 1,
isfriend: 0,
isfamily: 0
};
expected = 'https://farm2.staticflickr.com/1451/24770504484_69dd90d5dd_b.jpg';
actual = FlickrFetcher.photoObjToURL(input);
expect(actual).to.eql(expected);
});
});
I run the test, and it fails—sad cat.
Now that we have a new test, the question is, what is the simplest possible code we could write to make this test pass? With two tests the answer isn’t so simple. I could write an if- statement and return the second expected URL, but it’s almost the same amount of effort to write the general code, so I’ll do that instead.
// flickr-fetcher.js
FlickrFetcher = {
photoObjToURL: function(photoObj) {
return 'https://farm' + photoObj.farm + '.staticflickr.com/' + photoObj.server + '/' + photoObj.id + '_' +
photoObj.secret + '_b.jpg';
}
};
Run the tests again—happy cat. I have a working function.
We’re back to the refactoring step. Now, this code is still fairly simple, but all those plus signs look a bit ugly to me. One way to get rid of them would be to use a template library of some sort (like Handlebars or something lighter-weight), but it doesn’t seem worth adding the extra code just for this one function. Maybe I could try something else. If I put all the string parts into an array, I can glue them all together with the join() method. As an added bonus most JavaScript implementations will run array joins ever-so-slightly faster than concatenation. So I refactor to use join():
FlickrFetcher = {
photoObjToURL: function(photoObj) {
return [ 'https://farm',
photoObj.farm, '.staticflickr.com/',
photoObj.server, '/',
photoObj.id, '_',
photoObj.secret, '_b.jpg'
].join('');
}
};
I run the tests again, and my tests still pass, so I know everything works. Time to move to the next test…
At this point, if I were writing a module to be published with npm, I would now write tests to cover all the crazy things someone might pass this function. For example:
- What should happen if someone passes a string instead of an object?
- What should happen if someone passes no parameters?
- What should happen if someone passes an object that has the wrong property names?
- What should happen if someone passes in an object with the right property names but the values aren’t strings?
All of these are good questions to ask, and test, but I won’t go through that process here: Firstly because it would be incredibly dull to read, and secondly because this is a toy project that isn’t mission-critical for anything. I won’t be losing anyone’s money or endangering anyone’s life if this code doesn’t handle an edge case gracefully. For now, I know that it does what I want it to do. If I were however, writing life-support software or handling credit card details, or anything remotely like that, then I definitely want to answer all of those questions.
We’ve been through the full cycle with a working function: red, green, refactor. Now it’s time to pick the next test. Time to think. I want to take the list of photo objects that Flickr gives us and transform it into a list of objects that have just the information that I want. If I’m going to process a list, that will probably involve some kind of map operation, so I want to create a function that will just process one object at a time. That gives me another nice, small, testable unit of code to test. So, I write some test code:
// flickr-fetcher-spec.js
describe('#transformPhotoObj()', function() {
it('should take a photo object and return an object with just title and URL', function() {
var input = {
id: '25373736106',
owner: '99117316@N03',
secret: '146731fcb7',
server: '1669',
farm: 2,
title: 'Dog goes to desperate measure to avoid walking on a leash',
ispublic: 1,
isfriend: 0,
isfamily: 0
},
expected = {
title: 'Dog goes to desperate measure to avoid walking on a leash',
url: 'https://farm2.staticflickr.com/1669/25373736106_146731fcb7_b.jpg'
},
actual = FlickrFetcher.transformPhotoObj(input);
expect(actual).to.eql(expected);
});
});
When I run the test, I get an error because the function does not exist:
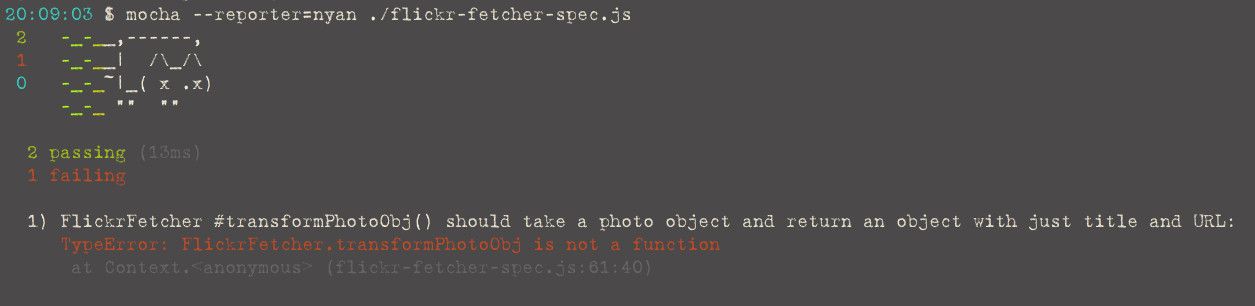
Now that I have a sad cat (red), I can write some code. What would be the simplest way to make this test pass? Again, just create a function that returns the expected result:
transformPhotoObj: function() {
return {
title: 'Dog goes to desperate measure to avoid walking on a leash',
url: 'https://farm2.staticflickr.com/1669/25373736106_146731fcb7_b.jpg'
};
}
I re-run the tests, and the cat is happy again (green).

Can I refactor this code? Or all my code? At this stage probably not. But, this code is not terribly useful, as it can only handle one specific input, so I need to write another test:
describe('#transformPhotoObj()', function() {
it('should take a photo object and return an object with just title and <abbr title="uniform resource locator">URL</abbr>', function() {
var input = {
id: '25373736106',
owner: '99117316@N03',
secret: '146731fcb7',
server: '1669',
farm: 2,
title: 'Dog goes to desperate measure to avoid walking on a leash',
ispublic: 1,
isfriend: 0,
isfamily: 0
},
expected = {
title: 'Dog goes to desperate measure to avoid walking on a leash',
url: 'https://farm2.staticflickr.com/1669/25373736106_146731fcb7_b.jpg'
},
actual = FlickrFetcher.transformPhotoObj(input);
expect(actual).to.eql(expected);
input = {
id: '24765033584',
owner: '27294864@N02',
secret: '3c190c104e',
server: '1514',
farm: 2,
title: 'the other cate',
ispublic: 1,
isfriend: 0,
isfamily: 0
};
expected = {
title: 'the other cate',
url: 'https://farm2.staticflickr.com/1514/24765033584_3c190c104e_b.jpg'
}
actual = FlickrFetcher.transformPhotoObj(input);
expect(actual).to.eql(expected);
});
});
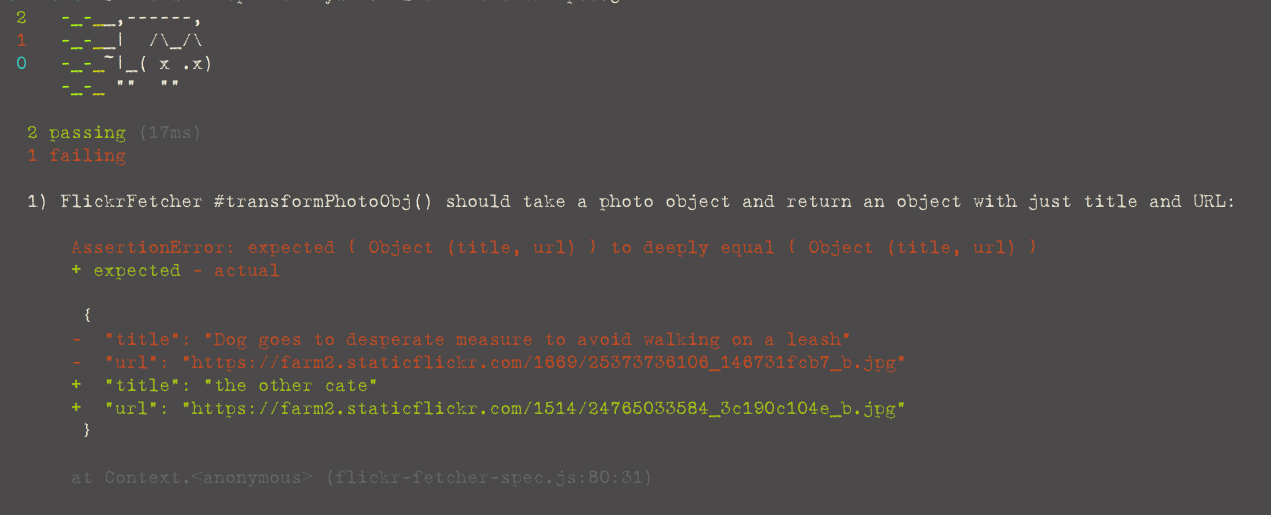
Now, the simplest, easiest way to make these tests pass now is to write the full function code, making use of the photoObjToURL() function I created earlier:
// flickr-fetcher.js
//… trimmed for brevity …
transformPhotoObj: function(photoObj) {
return {
title: photoObj.title,
url: FlickrFetcher.photoObjToURL(photoObj)
};
}
I run my tests again, and we have a happy cat (green).
Next is refactoring. Could this function be improved? At this stage, probably not. But it’s important to keep asking that question every time. Refactoring is one of the delicacies of programming and should be savoured whenever possible.
By now you should have a feel for the basic steps of TDD: Red, green, refactor. In this article we’ve looked at how to get started writing code with TDD. We’ve also looked at how it’s important to think before you write a test—TDD is no replacement for good software design. In the next two articles, we’ll examine how to handle asynchronous network calls and how to test DOM-manipulating code without a browser.